



Content
- Content
- What is Javadoc comment
- Limitations
- Tight-HTML rules
- How to create Javadoc Check
- Difference between Java Grammar and Javadoc comments Grammar
- Tool to print Javadoc tree structure
- Access Java AST from Javadoc Check
- HTML Code In Javadoc Comments
- Checkstyle SDK GUI
- Customize token types in Javadoc Checks
- Integrating new Javadoc Check
- Declare check's external resource locations
- Examples of Javadoc Checks
- Javadoc parser behavior for current HTML version and new HTML version
What is Javadoc comment
Javadoc comment is a multiline comment /* */ that starts with the * character and placed above the class definition, interface definition, enum definition, method definition or field definition. If an annotation precedes any of the definitions listed above, then the javadoc comment should be placed before the annotation. If several multiline comments with javadoc identifiers are placed sequentially, only the one closest to the definition, right above it, with the javadoc identifier will be used.
Javadoc comments should contain: a short summary (the first sentence), an optional documentation section, an optional tag section. The first sentence has a special meaning and should be clear, punchy, short, and is ended by a period symbol. Immediately after the first sentence, the main description could begin, which may be followed by the tag section. The tag section starts with the first block tag, which is defined by the first @ character that begins a line (ignoring leading asterisks, white space, and leading separator /**).
For example, here is java file:
/**
* My <b>class</b>.
*
* @see Annotation
*/
public class MyClass {
/** Not a javadoc (ignored). */
/**
* Doubles the value.
* The long and detailed explanation what the method does.
*
* @param value for doubling.
* @return double value.
*/
/*
Multiline comment (ignored).
*/
@Annotation
/** Extra javadoc (ignored). */
// Single line comment (ignored).
public int method(int value) {
/** Inner javadoc (ignored). */
return value * 2;
}
}
Javadoc content for the MyClass will be:
My <b>class</b>.
@see Annotation
Javadoc content for the MyClass.method will be:
Doubles the value.
The long and detailed explanation what the method does.
@param value for doubling.
@return double value.
Attention that java comment starts with /*, following with Identifier of comment type. Javadoc Identifier is *. All symbols after Javadoc Identifier till */ are part of javadoc comment.
Please note that javadoc-like (multiline comment with javadoc identifier) comment inside a method is not a javadoc comment and skipped by Sun/Oracle javadoc tool and by our javadoc comment matcher, but such comment will be in AST.
You can find different types of documentation generation tools similar to javadoc on the Internet. Such tools rely on specific Identifier: "!", "#", "$". Comments look like "/*! some comment */" , "/*# some comment */" , "/*$ some comment */". Such multiline comments are not a javadoc.
Limitations
Since Oracle itself does not provide a comprehensive language specification for Javadocs, we have interpreted the existing behavior of the Javadoc tool and accepted standards to form our Javadoc grammar and Abstract Syntax Tree (AST). For this reason, we must impose the following limitations on Javadoc parsing and checks.
The comment should be written in Tight-HTML to build ASTs that most Checks expect.
For more details about parsing of HTML into AST read HTML Code In Javadoc Comments and Javadoc parser behavior section.
Tight-HTML rules
Every HTML tag should have matching end HTML tag or it is a void element.
The only exceptions are HTML 4 tags whose end tag is optional (omittable) by HTML specification (example is TR), so, Checkstyle won't show an error about missing end tags, however, it leads to broken Tight-HTML structure and as a result leads to non-nested content of the HTML tags in the Abstract Syntax Tree of the Javadoc comment.
In other words, if HTML tags are not closed in Javadoc, our parser cannot determine the content of these tags, so structure of the parse tree will not be nested like it is while using Tight-HTML.
When a non-tight tag is encountered, the parser treats all subsequent text up to the next opening tag as the content of that unclosed tag. Once a new tag appears, it starts a new subtree instead of nesting inside the previous one, breaking the expected hierarchical structure of the AST.
Other rules:
- Document Structure elements (DOCTYPE, <html>, <body>, etc) are not mandatory.
- Elements must always be closed, except HTML4 elements whose end tag is optional (omittable) and HTML4 void elements. See HTML Code In Javadoc Comments section
- HTML elements can be either in lowercase or in uppercase
- Attribute names can be either in lowercase or in uppercase
- Attribute values can be either quoted or not be quoted
How to create Javadoc Check
Writing Javadoc Checks is similar to writing Java Checks, however you should extend AbstractJavadocCheck and use JavadocCommentsTokenTypes.
To start implementing new Check create a new class and extend AbstractJavadocCheck. It has two abstract methods you should implement:
- getDefaultJavadocTokens() - return int array of javadoc token types your Check is going to process. The array should contain int constants from JavadocCommentsTokenTypes class. (There is also TokenTypes class in Checkstyle. Make sure you use JavadocCommentsTokenTypes class in your Check, because the TokenTypes is used to describe standard Java DetailAST token type.)
- visitJavadocToken(DetailNode) - it's a place you should put tree nodes processing. The argument is Javadoc tree node of type you described before in getDefaultJavadocTokens() method.
Difference between Java Grammar and Javadoc comments Grammar
Our Java parser parses all multiline comments (C-style comments and Javadoc comments) as block comments, whether they are Javadocs or not. Our Javadoc parser then transforms these block comment ASTs into our Javadoc AST.
Our Java grammar ignores whitespace and newlines in most cases, since java itself does not care about whitespace; however, whitespace is critical in Javadocs. For this reason, our Javadoc AST retains most whitespace that is present in the Javadoc. (Empty TEXT, NEWLINE).
Tool to print Javadoc tree structure
Checkstyle can print a combined Java and Javadoc Abstract Syntax Tree. You need to run the checkstyle jar file with the -J argument, providing a java file.
For example, here is MyClass.java file:
/**
* My <b>class</b>.
* @see AbstractClass
*/
public class MyClass {
}
Command:
java -jar checkstyle-X.XX-all.jar -J MyClass.java
Output:
COMPILATION_UNIT -> COMPILATION_UNIT [5:0]
`--CLASS_DEF -> CLASS_DEF [5:0]
|--MODIFIERS -> MODIFIERS [5:0]
|--BLOCK_COMMENT_BEGIN -> /* [1:0]
| |--COMMENT_CONTENT -> *\r\n * My <b>class</b>.\r\n * @see AbstractClass\r\n [1:2]
| | `--JAVADOC_CONTENT -> JAVADOC_CONTENT [1:3]
| | |--NEWLINE -> \r\n [1:3]
| | |--LEADING_ASTERISK -> * [2:0]
| | |--TEXT -> My [2:2]
| | |--HTML_ELEMENT -> HTML_ELEMENT [2:6]
| | | |--HTML_TAG_START -> HTML_TAG_START [2:6]
| | | | |--TAG_OPEN -> < [2:6]
| | | | |--TAG_NAME -> b [2:7]
| | | | `--TAG_CLOSE -> > [2:8]
| | | |--HTML_CONTENT -> HTML_CONTENT [2:9]
| | | | `--TEXT -> class [2:9]
| | | `--HTML_TAG_END -> HTML_TAG_END [2:14]
| | | |--TAG_OPEN -> < [2:14]
| | | |--TAG_SLASH -> / [2:15]
| | | |--TAG_NAME -> b [2:16]
| | | `--TAG_CLOSE -> > [2:17]
| | |--TEXT -> . [2:18]
| | |--NEWLINE -> \r\n [2:19]
| | |--LEADING_ASTERISK -> * [3:0]
| | |--TEXT -> [3:2]
| | |--JAVADOC_BLOCK_TAG -> JAVADOC_BLOCK_TAG [3:3]
| | | `--SEE_BLOCK_TAG -> SEE_BLOCK_TAG [3:3]
| | | |--AT_SIGN -> @ [3:3]
| | | |--TAG_NAME -> see [3:4]
| | | |--TEXT -> [3:7]
| | | `--REFERENCE -> REFERENCE [3:8]
| | | `--IDENTIFIER -> AbstractClass [3:8]
| | |--NEWLINE -> \r\n [3:21]
| | `--TEXT -> [4:0]
| `--BLOCK_COMMENT_END -> */ [4:1]
|--LITERAL_CLASS -> class [5:0]
|--IDENT -> MyClass [5:6]
`--OBJBLOCK -> OBJBLOCK [5:14]
|--LCURLY -> { [5:14]
`--RCURLY -> } [7:0]
In most cases while developing Javadoc Checks, you need to only parse the tree of the exact Javadoc comment. To do that just copy Javadoc comment to a separate file and remove /** at the beginning and */ at the end. After that, run checkstyle with -j argument.
MyJavadocComment.javadoc file:
* My <b>class</b>.
* @see AbstractClass
Command:
java -jar checkstyle-X.XX-all.jar \
-j MyJavadocComment.javadoc
Output:
JAVADOC_CONTENT -> JAVADOC_CONTENT [0:0]
|--LEADING_ASTERISK -> * [0:0]
|--TEXT -> My [0:1]
|--HTML_ELEMENT -> HTML_ELEMENT [0:5]
| |--HTML_TAG_START -> HTML_TAG_START [0:5]
| | |--TAG_OPEN -> < [0:5]
| | |--TAG_NAME -> b [0:6]
| | `--TAG_CLOSE -> > [0:7]
| |--HTML_CONTENT -> HTML_CONTENT [0:8]
| | `--TEXT -> class [0:8]
| `--HTML_TAG_END -> HTML_TAG_END [0:13]
| |--TAG_OPEN -> < [0:13]
| |--TAG_SLASH -> / [0:14]
| |--TAG_NAME -> b [0:15]
| `--TAG_CLOSE -> > [0:16]
|--TEXT -> . [0:17]
|--NEWLINE -> \r\n [0:18]
|--LEADING_ASTERISK -> * [1:0]
|--TEXT -> [1:1]
`--JAVADOC_BLOCK_TAG -> JAVADOC_BLOCK_TAG [1:2]
`--SEE_BLOCK_TAG -> SEE_BLOCK_TAG [1:2]
|--AT_SIGN -> @ [1:2]
|--TAG_NAME -> see [1:3]
|--TEXT -> [1:6]
`--REFERENCE -> REFERENCE [1:7]
`--IDENTIFIER -> AbstractClass [1:7]
Access Java AST from Javadoc Check
As you already know the Javadoc AST is a result of parsing a block comment. There is a method to get the original block comment from a Javadoc Check. You may need this block comment to check its position in the DetailAST tree.
For example, to write a JavadocCheck that verifies @param tags in the Javadoc comment of a method definition, you also need all of the method's parameter names. To get a method definition AST you should access the DetailAST tree from a javadoc Check. For this purpose use the getBlockCommentAst() method that returns a DetailAST node.
Example:
class MyCheck extends AbstractJavadocCheck {
@Override
public int[] getDefaultJavadocTokens() {
return new int[]{JavadocCommentsTokenTypes.PARAMETER_NAME};
}
@Override
public void visitJavadocToken(DetailNode paramNameNode) {
String javadocParamName = paramNameNode.getText();
DetailAST blockCommentAst = getBlockCommentAst();
if (BlockCommentPosition.isOnMethod(blockCommentAst)) {
DetailAST methodDef = blockCommentAst.getParent();
DetailAST methodParam = findMethodParameter(methodDef);
String methodParamName = methodParam.getText();
if (!javadocParamName.equals(methodParamName)) {
log(methodParam, "params.dont.match");
}
}
}
}
HTML Code In Javadoc Comments
Checkstyle supports all HTML tags in Javadoc comments, including HTML4 elements and newer HTML5 tags. All tags are recognized by the Javadoc parser and represented using a generic HTML_ELEMENT token type, instead of specific token types for individual tags.
HTML4 defines two important categories of tags: elements whose end tag is optional (omittable) and void elements (also known as empty HTML tags, such as the BR tag).
HTML4 elements whose end tag is optional (omittable): <P>, <LI>, <TR>, <TD>, <TH>, <BODY>, <COLGROUP>, <DD>, <DT>, <HEAD>, <HTML>, <OPTION>, <TBODY>, <THEAD>, <TFOOT>.
Void HTML4 elements: <AREA>, <BASE>, <BASEFONT>, <BR>, <COL>, <FRAME>, <HR>, <IMG>, <INPUT>, <ISINDEX>, <LINK>, <META>, <PARAM>.
If a tag is unclosed and not a void element, it is considered non-tight. Non-tight tags prevent the Checkstyle Javadoc parser from creating nested AST structures. Always follow Tight-HTML rules to make the Checkstyle javadoc parser create nested ASTs.
<audio><source src="horse.ogg" type="audio/ogg"/></audio>
JAVADOC_CONTENT -> JAVADOC_CONTENT [0:0]
`--HTML_ELEMENT -> HTML_ELEMENT [0:0]
|--HTML_TAG_START -> HTML_TAG_START [0:0]
| |--TAG_OPEN -> < [0:0]
| |--TAG_NAME -> audio [0:1]
| `--TAG_CLOSE -> > [0:6]
|--HTML_CONTENT -> HTML_CONTENT [0:7]
| `--HTML_ELEMENT -> HTML_ELEMENT [0:7]
| `--VOID_ELEMENT -> VOID_ELEMENT [0:7]
| |--TAG_OPEN -> < [0:7]
| |--TAG_NAME -> source [0:8]
| |--HTML_ATTRIBUTES -> HTML_ATTRIBUTES [0:14]
| | |--HTML_ATTRIBUTE -> HTML_ATTRIBUTE [0:14]
| | | |--TEXT -> [0:14]
| | | |--TAG_ATTR_NAME -> src [0:15]
| | | |--EQUALS -> = [0:18]
| | | `--ATTRIBUTE_VALUE -> "horse.ogg" [0:19]
| | `--HTML_ATTRIBUTE -> HTML_ATTRIBUTE [0:30]
| | |--TEXT -> [0:30]
| | |--TAG_ATTR_NAME -> type [0:31]
| | |--EQUALS -> = [0:35]
| | `--ATTRIBUTE_VALUE -> "audio/ogg" [0:36]
| `--TAG_SLASH_CLOSE -> /> [0:47]
`--HTML_TAG_END -> HTML_TAG_END [0:49]
|--TAG_OPEN -> < [0:49]
|--TAG_SLASH -> / [0:50]
|--TAG_NAME -> audio [0:51]
`--TAG_CLOSE -> > [0:56]
This is an example of parsing an unknown tag that doesn't have a matching end tag (for example, HTML5 tag <audio>):
Input:
<audio>test
JAVADOC_CONTENT -> JAVADOC_CONTENT [0:0]
`--HTML_ELEMENT -> HTML_ELEMENT [0:0]
|--HTML_TAG_START -> HTML_TAG_START [0:0]
| |--TAG_OPEN -> < [0:0]
| |--TAG_NAME -> audio [0:1]
| `--TAG_CLOSE -> > [0:6]
`--HTML_CONTENT -> HTML_CONTENT [0:7]
`--TEXT -> test [0:7]
As shown above, the parser successfully recognizes all HTML tags, even if they are not explicitly defined in the HTML4 specification.
There are also HTML tags that are marked as "Not supported in HTML5" (HTML Element Reference). Checkstyle Javadoc parser can parse those tags too.
Example:
Input:
<acronym title="as soon as possible">ASAP</acronym>
Output:
JAVADOC_CONTENT -> JAVADOC_CONTENT [0:0]
`--HTML_ELEMENT -> HTML_ELEMENT [0:0]
|--HTML_TAG_START -> HTML_TAG_START [0:0]
| |--TAG_OPEN -> < [0:0]
| |--TAG_NAME -> acronym [0:1]
| |--HTML_ATTRIBUTES -> HTML_ATTRIBUTES [0:8]
| | `--HTML_ATTRIBUTE -> HTML_ATTRIBUTE [0:8]
| | |--TEXT -> [0:8]
| | |--TAG_ATTR_NAME -> title [0:9]
| | |--EQUALS -> = [0:14]
| | `--ATTRIBUTE_VALUE -> "as soon as possible" [0:15]
| `--TAG_CLOSE -> > [0:36]
|--HTML_CONTENT -> HTML_CONTENT [0:37]
| `--TEXT -> ASAP [0:37]
`--HTML_TAG_END -> HTML_TAG_END [0:41]
|--TAG_OPEN -> < [0:41]
|--TAG_SLASH -> / [0:42]
|--TAG_NAME -> acronym [0:43]
`--TAG_CLOSE -> > [0:50]
More examples:
| 1) Unclosed paragraph HTML tag. As you see in the tree, the content of the paragraph (<code> tag) tag is not nested within this tag. That is because HTML tag are not closed by </p>, and Checkstyle requires Tight-HTML code to predictably parse Javadoc comments. | 2) Here is a correct example with open and closed HTML tag. |
|
|
|
|
Checks can also be configured to log violations upon encountering non-tight HTML tags. The violateExecutionOnNonTightHtml property can be used for this purpose in the checks that support it. A custom check needs to extend AbstractJavadocCheck to have this functionality readily available. Do note that a check which has this property set to true, will log violations only for the first not-tight HTML tag found. To allow a check to skip processing of javadocs with non-tight HTML, the acceptJavadocWithNonTightHtml method in class AbstractJavadocCheck can be overridden in the check. The following example illustrates how to use this property.
Input:
/**
* <body>
* <p> This class is only meant for testing. </p>
* <p> This p tag is not closed. It is non-tight. Will lead to violations if
* <tt>violateExecutionOnNonTightHtml</tt> is set to true for the check.
* <li>tight li tag <p>non-tight p tag, but only the 1st non-tight tag is logged in violation</li>
* </body>
*/
public class Test {
/**
<p><p>
paraception. Will result in a violation from the <tt>JavadocParagraph</tt> check due to
redundant tags.
</p></p>
*/
private int field1;
/**<tr> `tr` tag is closed </tr>*/
private int field2;
/**
* <p> this paragraph is closed and would be nested in javadoc tree </p>
* <li> this list has an <p> unclosed para, but still the list would get nested </li>
*/
private int field3;
/**
* <li> Complete <p> nesting </p> </li>
*/
private int field4;
}
Output with violateExecutionOnNonTightHtml set to false:
|
|
Output with violateExecutionOnNonTightHtml set to true:
|
|
Checkstyle SDK GUI
The Checkstyle GUI provides us with a way to show javadoc trees in java files. To run it, use
java -cp checkstyle-13.8.0-all.jar com.puppycrawl.tools.checkstyle.gui.Main
and choose "JAVA WITH COMMENTS AND JAVADOC MODE" in dropdown list in bottom of frame.
Now you can see a parsed javadoc tree as a child of comment block.
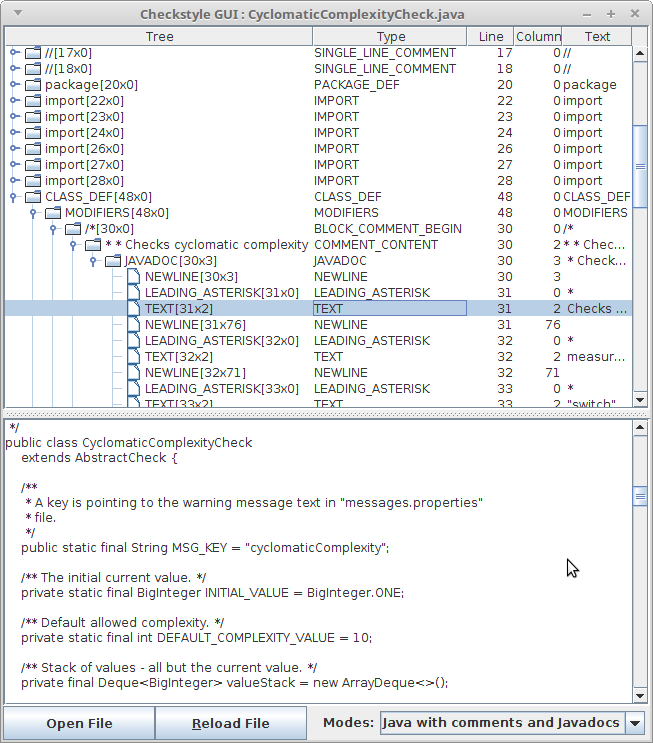
Notice that only files with ".java" extension can be opened.
For detail reference you can see Checkstyle GUI documentation .
Customize token types in Javadoc Checks
Java checks are controlled by methods setTokens(), getDefaultTokens(), getAccessibleTokens(), getRequiredTokens(). JavaDoc checks use the same model plus 4 additional methods for Javadoc tokens. As Java AST and Javadoc AST are not bound, it is highly recommended for Javadoc checks to not use customization of java tokens and except to be executed only on javadoc tokens.
There are four methods in the AbstractJavadocCheck class to control the processed JavadocCommentsTokenTypes - one setter setJavadocTokens(), which is used to define a custom set (which is different from the default one) of the processed JavadocCommentsTokenTypes via config file and three getters, which have to be overridden: getDefaultJavadocTokens(), getAcceptableJavadocTokens(), getRequiredJavadocTokens().
- setJavadocTokens() - method then define actual set of tokens to run on.
- getDefaultJavadocTokens() - returns a set of JavadocCommentsTokenTypes which are processed in visitToken() method by default.
- getRequiredJavadocTokens() - returns a set of JavadocCommentsTokenTypes which Check must be subscribed to for a valid execution. If the user wants to specify a custom set of JavadocCommentsTokenTypes then this set must contain all the JavadocCommentsTokenTypes from RequiredJavadocTokens.
- getAcceptableJavadocTokens() - returns a set, which contains all the JavadocCommentsTokenTypes that can be processed by the check. Both DefaultJavadocTokens and RequiredJavadocTokens and any custom set of JavadocCommentsTokenTypes are subsets of AcceptableJavadocTokens.
Integrating new Javadoc Check
Javadoc Checks as well as regular Checks extend AbstractCheck class. So integrating a new Javadoc Check is similar to integrating other Checks.
Declare check's external resource locations
Examples of Javadoc Checks
The best source knowledge on how to write Javadoc Checks can be taken from existing Checks .
Javadoc parser behavior for current HTML version and new HTML version
This section describes how the Javadoc parser handles HTML elements inside Javadoc comments. The parser now treats all HTML elements according to the same logic, there are no special token types and no version-specific parsing rules. All elements are parsed as GeneralToken which is represented in the AST as HTML_ELEMENT .
This unified behavior means that all HTML elements, including those introduced in newer HTML versions such as HTML5, are handled consistently without requiring special-case logic. The parser does not assign any special token types (such as PARAGRAPH or LIST_ITEM); instead, every tag is represented as a single HTML_ELEMENT node in the AST